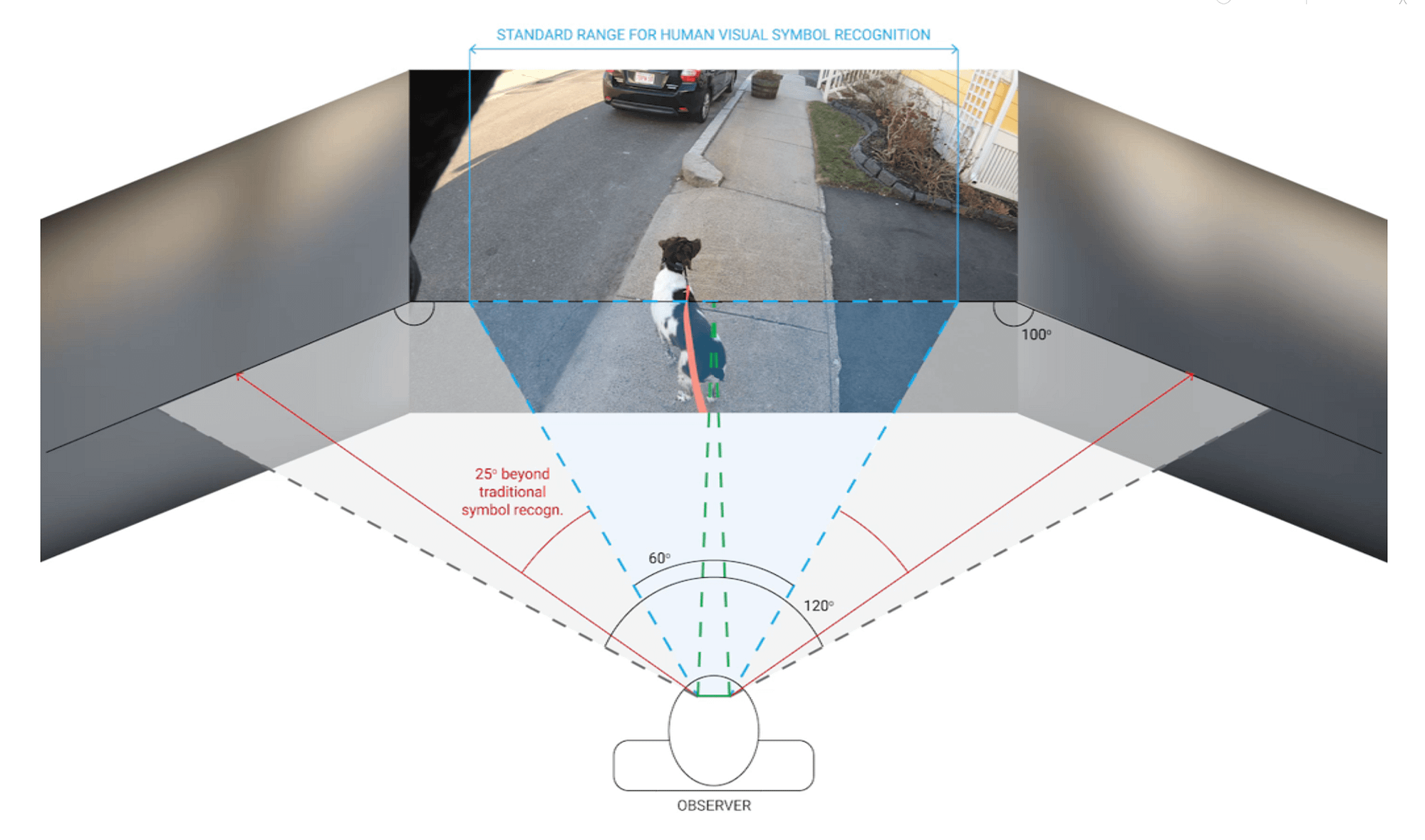
Increasing scene complexity: how detectable are far peripheral semantic cues in increasingly dynamic environments?
The focus of the experimentation conducted to evaluate the codex was two-fold:
- To measure detection metrics in a standard psychophysical setting, and
- To establish the feasibility of implementing this approach in dynamic real-world environments.
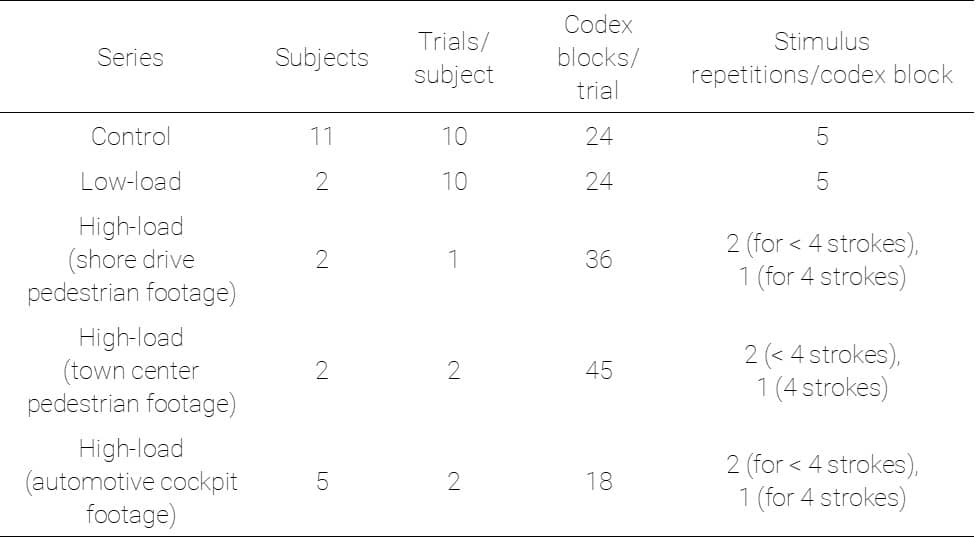
The study series first presented codex blocks with a standard 50 gray background and static central fixation (“control”). Next, in the low-load series, each codex block was evaluated with the same dynamic natural scene presented centrally, to normalize the effects of increasing scene complexity on codex perceptibility. Finally, three high-load environments were tested, in which codex blocks were presented in sequence over continuous video clips, with no normalization for variations in the scene.
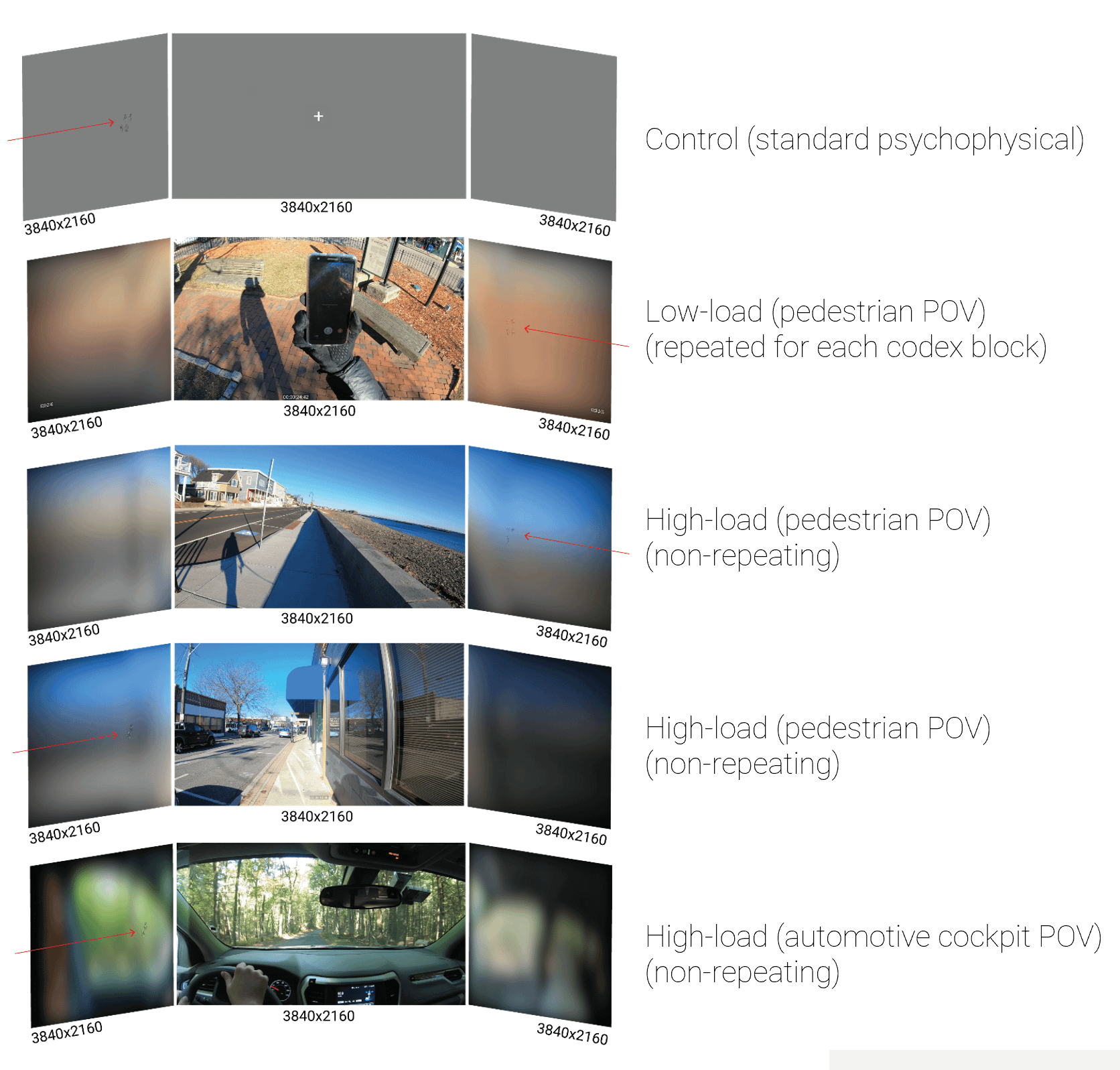
Study outcomes
Results show very little reduction in detection accuracy when transitioning from a 50-gray background with static fixation cues to a natural scene with uncontrolled changes in brightness, hue, and contrast. This table is a breakdown of accuracy metrics over successive trials in each study series.
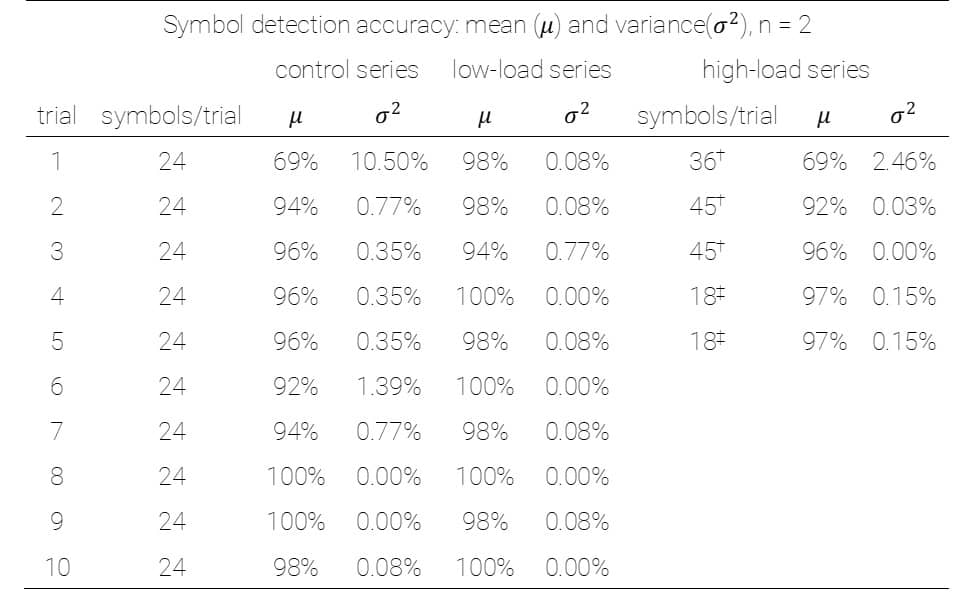
It shows mean detection accuracy dropped at first to levels comparable with the first trial in the control series, but rebounded just as quickly (see high-load series, trial 2 on the right-hand side of the table).
Detection speeds continue to improve despite increasing scene complexity
A subset of participants from the control series continued to complete trials in increasingly complex visual environments. An additional (n=2) completed a low-load series and two high-load series (from pedestrian continuing through automotive cockpit POV trial sequences), while another group of participants (n=3) completed the automotive cockpit POV, in addition to the control. Comparing these two groups allows us to evaluate whether continued exposure to the codex in environments, with gradually increasing complexity, resulted in improved detection rates.
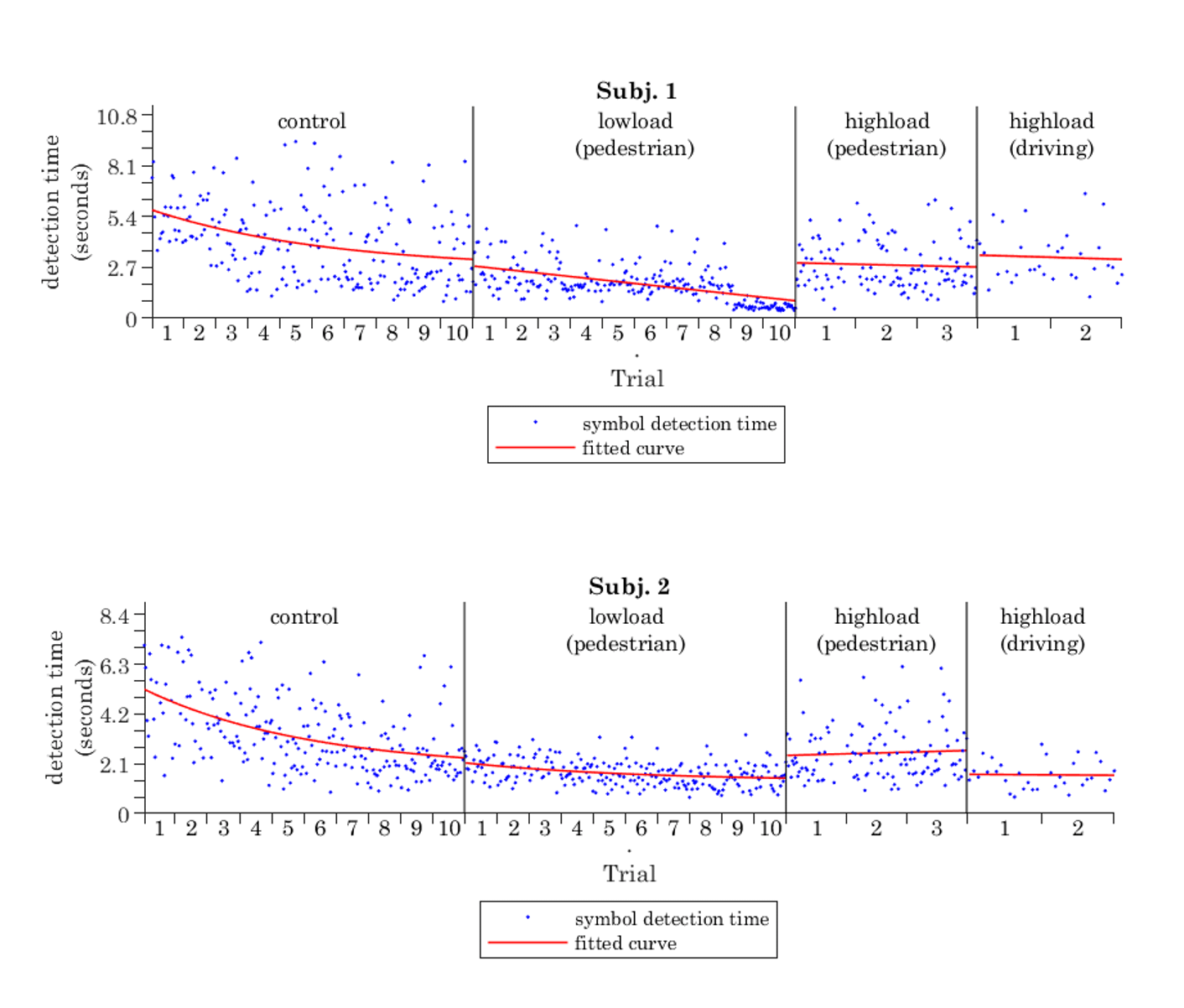
Both subjects who completed the low-load series in the pedestrian POV environment continued to improve in reported detection times over successive trials, despite the dramatic shift from a static 50-gray background and static fixation to a dynamic natural scene. Notably, fitted trends show close continuity throughout the series, especially near the end of control trials and beginning of low-load series.
In addition to continued downward trends in the low-load case, both subjects exhibited a substantial decrease in variance of recorded detection times. These outcomes from the low-load series represent the first demonstration of far peripheral complex symbol recognition in dynamic visual environments. High accuracy rates and continued improvements in detection speed in low-load series build a strong foundation for feasibility and practicality of implementing motion-modulated peripheral stimuli for semantic information delivery outside of controlled psychophysical environments.
Is exposure to the control environment sufficient priming to improve outcomes in complex environments?
To evaluate the extent of visual learning accomplished by the control series, three additional subjects completed high-load driving trials, *without* any additional studies in between.

To compare outcomes between these two groups, an improvement factor was calculated between the first trial of the control series and the high load driving series, as shown in the first row of the table here. Comparing outcomes for group 1 and group 2 shows there was no significant difference in their improvement factors (p = 0.76).
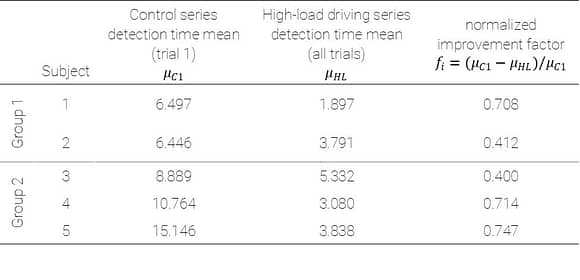
Similar performance between these groups suggests sufficient priming on the codex occurred during the control series to prepare subjects for dynamic visual environments beyond the standard psychophysical backdrop. These initial findings illustrate a significant potential toward establishing a visual learning model with a broader group of subjects in subsequent trials, yielding a more complete characterization of training necessary for achieving high symbol detection accuracies in real-world scenarios.